��ι������ɵصĔ������ģ�
���ߣ��W�j�D�d �l���r�g��[ 2012/1/6 10:35:57 ] ���]�˺���
�I�պ�������ʹ�Ô������Ĺ����͞��y�֏͵�ȱ�ݸ������@����ʮ��ǰ����؛܇�\ݔ�Ŏ��M�д惦�ܝM�������ˡ�ʮ��ǰ���ɂ��������ĵľ��xֻҪ���M��I/O���ܝM�����F�ڣ��S������̄ճɞ���Ҫ��ؓ�d���֏�Ӌ��߀�ÿ��]�������ĵĵ������x���@һ�c�����˻֏͕r�g��
�������x�c����������
�����ϣ��@���P�ڃɂ���ͬλ�õĔ������ģ���D1��ʾ���ڔ�ĿҲ�S���Uչ������վ�c��
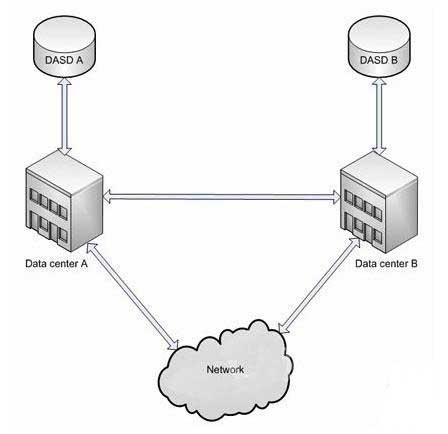
�D1�������Է��x�������ĵ�ʾ��D
�D�Ѓɂ����������Ƿ��x�ģ��@�����M��ͬ���űPݔ��ݔ�����f������̫�h�ˣ��@�����˺ܶ���������ÿ���������ı�횵����Լ���ֱ�Ӵ�ȡ�惦�O�䣨Direct Access Storage Device�����QDASD���������M�й������ڶ���ͬ��Ӳ�����ƕ����W�j���t���o�����������xҲ��ζ����ÿ���������ĵ�߉�օ^��logical partition�����QLPAR������̎��ͬһ��Sysplex��Systems Complex��ϵ�y���w�����档
�W�j�ڔ������Ĺ�����ռ����Ҫλ�ã��ǃɂ���������֮�g���ГQ�_�P�����˺��m�ăȲ�ͨӍϵ�y���Ժ��Ҫ���Ի��ڲ�ͬ�˜ʣ���·���ֽoÿ���������ġ��䌍�����ˬF�ڻ��ڞg�[���đ��ã��Ñ����Ԍ��F��ͬ�������ĵIJ��g���ГQ��
���Ӳ�����Ʋ����ã����������߉����������L����ʽ��access method���ļ��e�ϱ��@ȡ���Ўׂ��aƷ�������@���¡����֮aƷ��ͨ�^�x�������Virtual Storage Access Method�����QVSAM��ӛ䛁�������׃��Ͷ�������������ģ�ͨ�^ͨ�ž�·ʹ�ö�N�Ă�ݔ�f�h���ڽ��նˣ�����һ��ܛ���l�o��������L����ʽ���������h��������
�����ɵصĔ�����������
���x�Ĕ��������кÎN��ʽ�����ã����뵽�������N��
Hot-warm
��I��һ���������ı�ָ�ɳɞ����оW�j������Ŀ�ˡ��ڵ�һ���������ĵ������������Ƶ��ڶ�����������վ�c���ڶ��������ղ����@Щ��׃���ڱ��ص�DASD������һ����һ���������Ĺ��ϣ����ڶ���վ�c�ھ�����y�������͡�
����-��ԃ
������-��ԃ�ķ����У�һ���������ĵ^ȫ�w������������ֻ���S��ԃ��������վ�c��ֻ�x��ϵ�y���w���r������׃�����������������ʧ����ؓ؟��ԃ��ϵ�y���w��ؓȫ؟��
�W�j���M���@�N���b�r����Q�������ã�������܆���Ϣ���ݣ���^��ԃ���������ա�����վ����Ҳ��ʹ�þW�j��ƽ��ؓ�d��ʹÿ�����������܉��ό����Լ���ֻ�x������
����-����
�@�ǂ��������ڵ��¡�ÿ����������֧�����Д����������������ɷN��ʽ�ď�������ͨ���B�ӣ����֔������ͬ����һ���l�����ϣ��]�г����}�Ĕ������ijГ����м���������������
ע�⮔�ɂ��������Ķ������r��������߉�Ͽ��ܕ����x�������f���Ñ��ij������������������Ⱥ���߅�ġ�A�������ġ����ڶ���ֻ�x�Ĕ����ڡ�B�������ġ����Ñ�����һ߅�������Ƿ���ġ��K���@��ζ���W�j���������ܣ�֪���͑��ij����������ġ�
�������}
���Ÿ�λ��˼��]���x���ѽ��뵽�����@Щ���}������߀�и������˲����IJ��������ء�
��̎��??������-������ģʽ�£����a�������}��ࡣ��I�ÛQ����һ���M����̎���������̎��ɷ������M�и��^���ˡ�߀�ÿ��]���������������ԏ�I/O���P��̎�����ДD�����g������ͨ�^����朽ӡ�
���Ƶ����t??�F��ͨ���B���ֿ��пɿ�����߀���І��}�����ǿ�������ͨ�ž�Ҳ���ܺ�DASD I/Oһ��ͬ���Ϳ��١���ˣ�ϵ�y���A�ܘ���һ���֑��ñ�횜ʂ�Ñ������t�͡��^�r���Ĕ�����
�_ͻ���}??���������ϵ�y��Database Management Systems�����QDBMS���ڲ�ͬ��ϵ�y���w�У�����̫���ľ��x�i��������ӛ䛡��@�����ڲ�ͬ�������ăȣ���ͬ�Ĕ�����ӛ䛿��ܕ�ͬ�r���������A�Oʩ�͑�����Ҫ�ʂ�Ñ�����y��
���Ƹ�׃??���A�Oʩ�����ú͔������OӋ�ĸ�׃һ�����J������������Ɖ��ڲ�ͬ�������ď��Ƶ�һ���ԡ�
Ư��??�]�Ю������Ƽ��g��߉I/O�����������ģ���I���l�F�ֲ攵���惦׃���������@Щ��ͬ��Ҫ�����Ե��{���M�̡�
����??���ڔ������ā��f��ʲô��������������ͨ�^����������heartbeat������ϵ�����Ǐ��������Ĝp�������Aʾ��һ���������Ĺ����������ˡ�ͬ�ӵأ�һЩ�z���heartbeatҲ��ʾ���W�j���ϻ�p���������ǔ������Ĺ��ϡ�
̽��������@Щ���X���Ĺ��ρ����£�Ҫ���IJ߄������ߡ��߶��Ԅӻ����м��Ĺ���������Ϣ�ǔ������ĵĵ������x��u׃��ƽ������Q�@Щ���}������Ҳ׃�ø��ӱ��ڌW����
���P���]











���°l��
���ܜyԇ֮�yԇ�h����ķ���
2020/7/21 15:39:32ܛ���yԇ�Ǐ�ʲô�r���_ʼ����I����ҕ���أ�
2020/7/17 9:09:11Android�Ԅӻ��yԇ�������Щ����ʲô��;��
2020/7/17 9:03:50ʲô�ӵ��Ŀ�m�����Ԅӻ����Ԅӻ��yԇ�ˆT���߂����ӵ�������
2020/7/17 8:57:06�״������������ܜyԇ���ߜy�u
2020/7/17 8:52:11RPA�C�����܉����푑���I��������ô�����ģ�
2020/7/17 8:48:05Bug��������������ʲô?
2020/7/17 8:43:03ܛ���yԇ������������ô���ģ�ܛ���yԇ�������ڵ��γɚv����ʲô��
2020/7/16 9:11:10
 sales@spasvo.com
sales@spasvo.com