��������{�×��������еģ�MyMethod>M1>M2>M3>M4��������2a���O�õ��^�V�l�������ܽ��������@ʾ���µ��{�×���MyMethod>M1>M2>M3�������@ʾ��һ���{��M3>M4����鳬�^��3�ӣ������D��ʾ
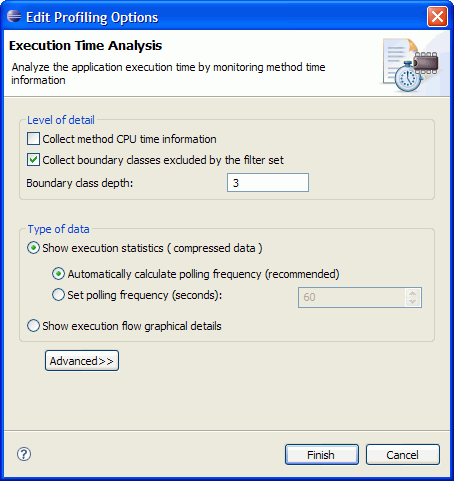
����3.�x��Ҫ�������
��Moniter��У��x��Java Profiling헣�Ȼ���p�����߆Γ������o�����_The Filter Set ������The Filter Set ������x��������������@���ѽ��A�ȶ��x��һ�M���õ��^�V�����������f�������ͨ�^����ײ�����һ���µ��^�V����
����3a���Γ�Add..���o���ڏ����Č�Ԓ����ݔ��ProductFilterSet��Ȼ��Γ�OK��
����3b)ʹ��Contents of selected filter set�б��е�Add���o���Ӄɂ��^�V�������D��ʾ��
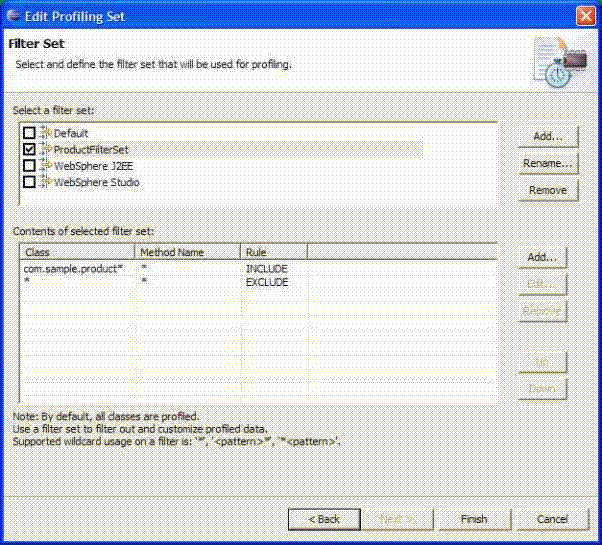
���\���
����ͨ�^��Launch Configuration wizard�����c��OK���o���\��Product catalog ������ԃ���Ƿ��ГQ��Profiling and Loggingҕ�D�r�x��Yes���㌢��Consoleҕ�D�п������D��ʾ�ĽY����
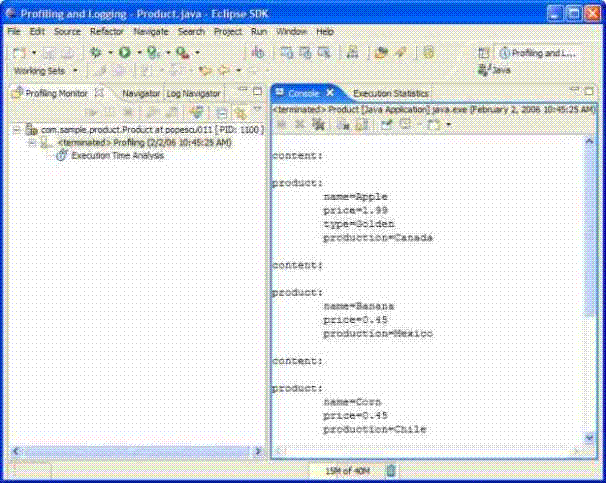
����ʾ��TPTP���ܜyԇ�������S������������ij���֮�g���������ܕ�ͣ���֏ͱO ���\�������ռ����Ռ������û�����ֹ������\�С�
��ʹ��Execution Statisticsҕ�D��������Σ�U�c
��ʹ��Execution Statisticsҕ�Dȥ��������Σ�U�c����Profiling Monitorҕ�D�У����I-->Open with > Execution Statistics���Դ��_Execution Statisticsҕ�D���D�@ʾ���ǰ��շ����{�õ��۷e�r�g����ģ��۷e�r�g��ָԓ�������M�����Еr�g�������{���������������ĵĕr�g��
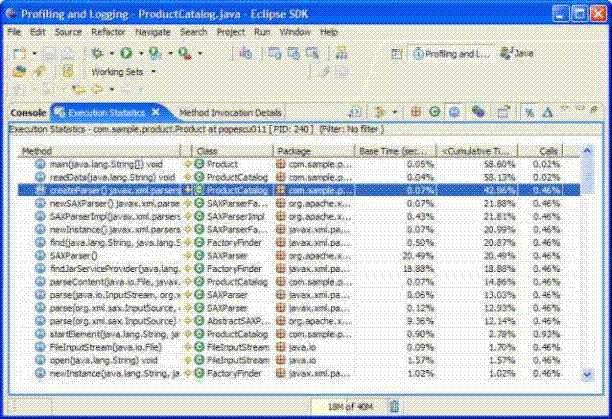
�� �����ψD��ʾ��Execution Statistics �@ʾ���Ϸ��ķ�����main(java.lang.String[])�� readData(java.lang.String) ��createParser() �����˶�Ĉ��Еr�g����Ҋmain��readData�������б��У���λ�ã��Dz���ֵģ����ǰ���dz�����е��_ʼ�c�����ߏ������ֿ��Կ�������xml�ļ����xȡ�aƷ��Ϣ��
��ʹ�҂��X����ֵ��Ƿ���createParser() �����H�H���������ڽ���xml�ļ���SAX parser �������M����˸ߵĈ��Еr�g��ԓ�����Ĉ��Еr�gռ���������õĈ��Еr�g��42.96%��Execution Statistics �����҂������@�����������܃����ĝ��ڵĵط���
���������@��҂�����createParser() �����Ĉ��м�����

