�����������Ŀ���������M��Kֵ������
������ Kֵ�����Dz�׃�ģ������S���ӱ������������ڲ����׃���������҂����Ԍ��H�Ŀ��������������Kֵ��׃����r��ԭʼ����������78���yԇ�Y���ǵõ�100���A�y�c�������ֻ���]Gompertzģ�ͺ�Logisticģ�͡�
������ �yԇ�_ʼ���ڣ��H��9�������r�M���A�y����D2
�����x��9��������������ͷ��������Ļ���Ҫ��“�ӱ�������������9��”�������҂��x�����c��9�������c����u��ֵ���������c��
�����ĈD2�п��Կ�����9�������r���ӱ��������۷eֵ��100���A�yֵ����K����187.0��103.5���@��ζ���ӱ���څ��ֵ��187.0��103.5������100�������r�������l�F187.0��103.5��ȱ�ݡ�Gompertzģ�ͺ�Logisticģ�Ͷ��^����Ϙӱ�څ�ݣ�Gompertzģ���Ժá�
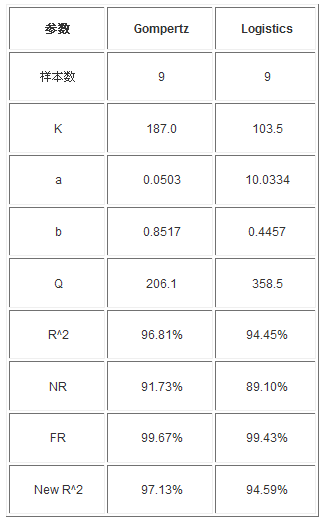
�D2 9���ӱ������r���A�y
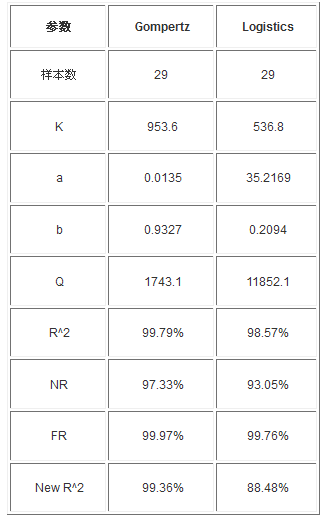
�D3 29���ӱ������r���A�y�D
������ �yԇ���M�У�Gompertzģ�͔������ӵ�29���r�M���A�y����D3
�����x������29��ԭ�������ó���Gompertzģ�͵Ĺ��c���F�ڴ�s��37%��1/e����λ�á��@���҂�ʹ�õĚvʷ����������78������˵õ����c��λ�ô���ڵ�29����
�����ĈD3�п��Կ�����29�������r���ӱ������۷eֵ��555����Ҋ֮ǰ�A�y�õ���K��187.0��103.5�������ٷ���څ�ݡ��˕r��Gompertzģ���A�y����Kֵ��953.6��Logisticģ���A�y����Kֵ��536.8���@��ζ���ӱ���څ��ֵ��953.6��536.8������100�������r�������l�F953.6��536.8��ȱ�ݡ��@�r��Gompertzģ�ͺ�Logisticģ�Ͳ�^�ĸ����M�϶�ָ�˼��ӱ������۷eֵ������Gompertzģ���á����ǣ�����У�Logisticģ�͵Ĺ��c������37%̎��������50%̎��

