������ �yԇ���M�У��������ӵ�39���r�M���A�y����D4
�����x������39������@��Logisticģ���c��λ�á����^Ӌ�㣬45�������r���ӱ������۷eֵ��763��֮ǰӋ�����Kֵ�ٴ��C��������څ�ݡ��ĈD4�п��Կ�����Gompertzģ���A�y���A�yֵ��1074.0��Logisticģ���A�y����Kֵ��707.9���@��ζ���ӱ���څ��ֵ��1074.0��707.9������100�������r�������l�F1074.0��707.9��ȱ�ݡ��@�r��Gompertzģ�ͺ�Logisticģ�Ͳ�^�ĸ����M�϶�ָ�ˁ�������Ȼ��Gompertzģ���á�
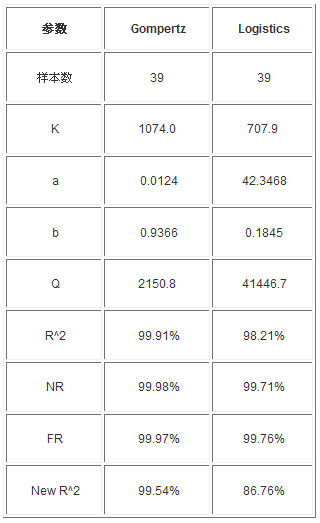
�D4 39���ӱ������r���A�y�D
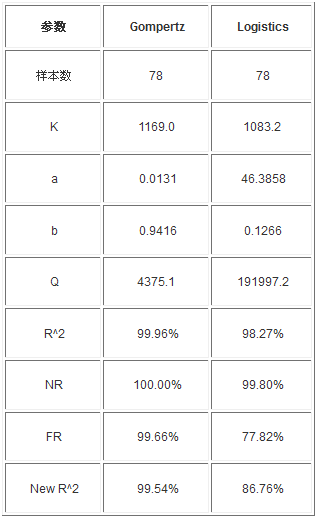
�D5 ȫ���ӱ�����Ӌ��õ����A�y�D
������ �yԇ���M�У��������ӵ�78��Ҳ��ȫ���Ęӱ���������D5
�������^Ӌ�㣬ȫ���ӱ��������۷eֵ��1123��֮ǰ�yԇ����Kֵ��1167.1��976.3���е�1167.1���ܷ���څ�ݣ�����Ȼ��Ҫ�M���A�y��C���ĈD5�п��Կ�����Gompertzģ���A�y���A�yֵ��1169��Logisticģ���A�y����Kֵ��1083.2������Logisticģ���A�y����Kֵ�ڶ�Ό���ж�С�ژӱ��۷eֵ�������Д��Logisticģ�Ͳ������Ͻo���ӱ���څ�ݣ��@Ҳ��ζ���ӱ���څ��ֵ��Gompertzģ���A�y�õ���Kֵ����1169������100�������r�����l�F1169��ȱ�ݡ�
�����ɴ˿�Ҋ��Kֵ��׃��څ�ݽ��v�˲������L��һ���^�̣��IJ������ӣ���څ�ڷ�������D6���˕r��K��׃����r������ָ��������
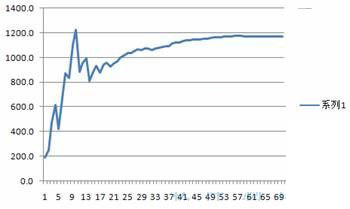
�D6 �u��ֵK��׃��څ��

